 A Computer Simulation and Monitoring Method for Taiwanese Tone Sandhi
A Computer Simulation and Monitoring Method for Taiwanese Tone Sandhi
A Computer Simulation and Monitoring Method for Taiwanese Tone Sandhi
台語變調的電腦模擬與監測方法
Yu-chu Chang
Nanhua University, Taiwan
poirotdavid@yahoo.com.tw
Abstract
This research employs knowledge representation methods to simulate intra-sentence tone sandhi in Taiwanese. The developed system integrates a Taiwanese Tone Group Parser with a simulation-monitoring interface, utilizing expert system techniques and linguistic expertise to construct a robust tone sandhi processing model. The significance of this study is summarized in three core aspects:
First, it proposes the Tonal Derivation Strategy, demonstrating that word tone determination and tone group boundary identification are mutually causal processes. This is verified through the implementation of a parser that achieves high-precision segmentation. Second, it illustrates the conversion of linguistic experience into a structured knowledge base using default tone forms, default parts of speech (POS), and context mode marks. It explains the process of allotone seletion determination through the connection between the inference engine and the knowledge base. Finally, it further optimizes debugging efficiency through a simulation monitoring program. Through an inference engine, the system addresses the complex one-to-many mapping inherent in tonal languages—a persistent bottleneck for purely statistical models. The research utilizes a rule-based expert system for iterative optimization; after ten rounds of supervised refinement, outside testing on random articles yielded an average tone sandhi accuracy of 96% to 98%.
Beyond technical metrics, this study argues that language structure serves as the "logical skeleton" of AI. Purely data-driven deep learning models often fall into the "average value trap," leading to phonological breaks and the loss of linguistic nuance. By adopting a Hybrid Architecture where an expert system serves as a precise front-end to override or guide probabilistic outputs, we can reduce computing requirements while ensuring cultural authenticity. In conclusion, preserving the intricate rules of Taiwanese tone sandhi is not merely a task of software engineering but a defense of an endangered "thinking structure." If AI can faithfully process the phonological logic of Taiwanese, it represents a significant milestone toward developing machines that truly simulate the diversity and depth of human intelligence.
Keywords: Computer simulation, Taiwanese tone sandhi, Expert system, Tone group parser, Automatic tagging, Hybrid Architecture, Linguistic Diversity.
Contents
1 Introduction
1.1 The Crucial Role of Tone Sandhi in Linguistic Identity
1.2 The Tonal Derivation Strategy and Expert Systems
1.3 Problem Statement and Significance
2. Literature Review
2.1 The Nature of the Taiwanese Language: Phonological and Structural Perspectives
2.2 The Properties of Taiwanese Tone Sandhi and the Formation of Tone Groups
2.3 Rule-based Expert Systems
2.4 Knowledge Representation Methods and Examples of Linguistic Simulation
2.5 Deep Learning Methods and Modern Natural Language Processing
2.6 Current Research on Taiwanese Tone Sandhi and Text-to-speech System
3. The Development of Tonal Derivation Strategy
3.1 The Dilemma: Syntactic Analysis or Tone Form Analysis First?
3.2 Use of Medium Language
3.3 Tonal Derivation Strategy
3.4 From Tonal Derivation Strategy to Developing a Feasible Method
4. Methodology
4.1 Application of Knowledge Representation Method
4.2 Use Romanized Taiwanese as the written language
4.3 Frame-based Corpus
4.4 The Tagging of Markup Symbol and Rule Construction of Tone Sandhi Processor
4.5 The Configuration and Management of Program Memory
4.6 Capturing Tone Groups from Taiwanese Sentences
4.7 Designing a Tone Group Feedback Function
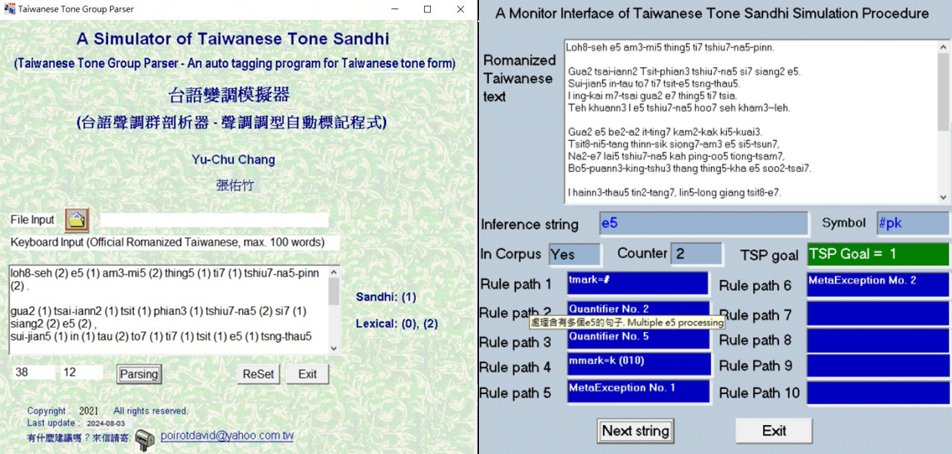
4.8 Monitoring Interface
5. Implementation of Taiwnese Tone Sandhi Simulation System
5.1 Coding Procedure
5.1.1 Overview of the Programming Workflow
5.1.2 Practical Coding Procedure
5.2 Construction of Tone Sandhi Processor
5.2.1 How to Build Tone Sandhi Rules
5.2.2 Rule Interference
5.2.3 Instantiation of the Rule Base
5.2.4 Boolean Verification
5.3 Recursive Feedback Mechanism of Tone Group
5.4 Monitor Interface for Processing Tracing and Debugging
5.5 Function of the Inference Engine
5.6 Application of Simulation Data
5.7 Output of the simulator
5.8 Evaluation of Tone Sandhi Accuracy Test
5.8.1 Testing Materials
5.8.2 Results of Tone Sandhi Accuracy Test
5.8.3 Connection Test of Tone Group Parser and Text-to-speech Software
5.9 Ultimate Solution to Tone Sandhi Error
6. Discussion on AI Models and Taiwanese Language Processing
6.1 The Relationship Between AI Model Diversity and "Language as Thought"
6.1.1 Language structure as the "logical skeleton" of AI
6.1.2 Breaking the monopoly of a single truth: the necessity of diversity
6.1.3 Modern interpretations of Chomsky and Piaget
6.1.4 Insights from these perspectives
6.1.5 Integration of Traditional and Modern AI Models
6.2 The Impact of Modern AI Models on Language Processing
6.2.1 The probability collapse of "One-to-Many"
6.2.2 Distortion of Western Linguistic Theories
6.2.3 The Irreplaceability of Expert Systems
6.3 Establishing a Hybrid Architecture
6.3.1 Quantitative comparison of sandhi accuracy (Estimated)
6.3.2 Bottlenecks of Deep Learning in Taiwanese Sandhi
6.3.3 Why "Override" is the best current solution
6.3.4 Metrics beyond Mean Opinion Score (MOS)
6.4 Literary Chinese (文言文)— The Pure Prototype of Taiwanese Phonological Logic
6.4.1 Stability of Tone Group structures
6.4.2 Harmonizing "Layers": Attribute switching for Literary vs. Colloquial readings
6.4.3 Evidence of resistance to assimilation
6.5 Tone Sandhi Adaptability in the Taiwanese Phonological System
6.5.1 Sanskrit Transliteration (Buddhist Sutras): Rhythmic Syllabification
6.5.2 Japanese Loanwords: Multi-layered Assimilation
6.5.3 Grammaticalization of Western and Indigenous (Siraya) Toponyms
6.5.4 The Principle of "Conventional Usage" (從眾從俗)
6.5.5 Data Availability and the Feedback Loop
6.5.6 Pragmatism in Standardization
6.5.7 Dynamic Knowledge Base
6.6 Why Expert Systems Better Handle "Adaptability" Than Deep Learning?
6.6.1 The Phonological Code of "Oden": Why the 7th Tone?
6.6.2 Grammaticalization and Utility of Transliterated Terms
6.6.3 Taiwanese TTS and the "Seamless" Experience
6.7 Research Goals
6.8 AI Model Diversity from the Perspective of Knowledge Representation
6.8.1 Why the "Foreign Word Correspondence Table" is Key to AI Diversity
6.8.2 Protecting Digital Sovereignty and Cultural Logic
7. Conclusions and Future Outlook
7.1 Conclusions
7.2 Future Outlook
Glossary
References
摘要
本研究旨在應用知識表徵方法來模擬台語句內連讀變調。此模擬系統包括台語聲調群剖析器和模擬監控介面。採用專家系統技術結合語言知識和專業經驗來創建變調處理模型。這項研究的意義主要在於三個方面:
首先,我們提出聲調推導策略,認為確定句內語詞的聲調調型就可以決定台語聲調群的分界,並以高精度的聲調群剖析器實作加以驗證。其次,描述如何使用預設聲調調型、預設詞類和語境模式標記,將語言知識和經驗轉化為知識庫,並說明經由推論引擎與知識庫的連結,完成語詞定調的運作過程。最後,經由模擬監控程序,進一步優化除錯效率。透過推理引擎,該系統解決了聲調語言中固有的複雜的一對多映射問題;這是純統計模型長期面臨的瓶頸。本研究利用基於規則的專家系統進行迭代優化;經過十輪監督式優化後,對隨機文章進行的外部測試顯示,聲調連讀的平均準確率達到 96% 至 98%。
除了技術指標之外,本研究也指出,語言結構是人工智慧的「邏輯骨架」。純粹的數據驅動型深度學習模型常常陷入“平均值陷阱”,導致語音斷裂和語言細微差別的損失。透過採用混合架構,以專家系統作為精確的前端來覆蓋或引導機率輸出,我們可以在確保文化真實性的同時降低運算需求。總之,保留台語連讀聲調的複雜規則不僅是軟體工程的任務,更是對一種瀕危「思維結構」的捍衛。如果人工智慧能夠忠實地處理台灣語的語音邏輯,這將是朝著開發真正模擬人類智慧多樣性和深度的機器邁出的重要一步。
關鍵字:電腦模擬,台連讀變調,專家系統,聲調群剖析器,自動標註,混合架構,語言多樣性。