 坐牛車(2600R)
正月的西瓜 (3060R)
露背裝的故事 (2600R)
坐牛車(2600R)
正月的西瓜 (3060R)
露背裝的故事 (2600R)
1. 前言
2. 系統特色與功能
3. 程式架構說明
4. 開發過程摘要
5. 安裝
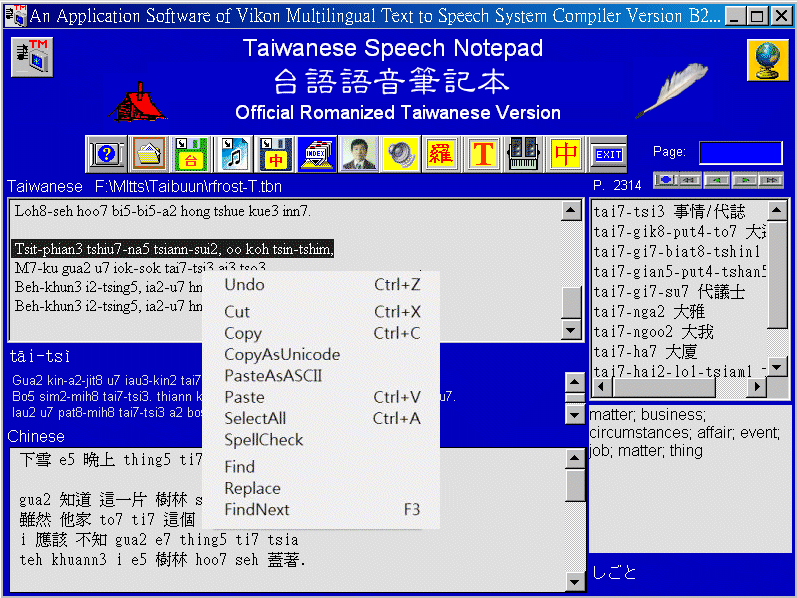
6. 使用方法簡介
7. 圖形操作介面說明
8. 結語
9. 誌謝
10. 備註
十多年前,台灣坊間幾乎看不到口語化的台文作品,一般人也認為台語就是中國的閩南方言,根本無法書寫。台語真的無法書寫嗎?其實,台語一直有文白兩套語音系統。讀書人用的文音可直接以漢文寫出,例如文言文、漢詩或唐宋詩詞等。至於日常庶民所用的白話音則與現代中文有相當差異,當然無法完全以中文白話書寫。從台灣文獻可知,早在一百多年前 (1875) 台灣的基督徒就用羅馬字來寫台灣話 (通稱白話字或教會羅馬字)。甚至更早的三百多年前 (1661) 荷蘭人也用羅馬字為台灣平埔族原住民建立新港語的聖經書。白話文由於不能用打字機繕打,戒嚴時期又被統治者查禁,所以只在基督教會間通行。解嚴以後,各種台語系統紛紛出土,個人電腦也可以處理白話文或音漢併用的「漢羅文体」。不過白話文和漢羅文体在文書處理和電腦應用方面仍然不若純英文字母的拼音系統方便,主要還是聲調記號和文字編碼的問題。
圖 (一) 教育部台語羅馬字版操作介面
自然語言電腦化,必須處理「聽、說、讀、寫」四種功能。聽和說的應用尚未普及;原因是除了語音辨識和分析技術以外更需仰賴人工智慧的邏輯推理和機器學習能力,目前仍在實驗階段。至於讀和寫,在實用上則比較成熟。「語音輸出引擎」 (Text-to-speech engine) 加上一部雙語辭典和簡單的文書處理器便可組合成雙語讀寫系統。台語電腦化,主要的關鍵有三;第一、文字碼最好能和 ASCII 碼相容,電腦處理時才不會有字碼衝突的問題。第二、建立人工的聲調群剖析器,才能正確地標出台灣話的八個聲調 (註 1)。第三、語詞和構詞法必需標準化,各種拼字法間可以規則互換,才有大量現成的辭典、語詞、語料和文字作品可供引用。至於台語和漢語間的互譯,則有賴於語法規則的建立,這方面的研究,仍有待努力。
本文除了敘述系統功能、程式架構和操作程序外,並就開發過程及心得作扼要說明。
系統特色有五:
一﹑與 Windows 作業系統相容。
二﹑使用圖形介面,國小學童即可操作,不需特別訓練。
三﹑自然語音輸出 (教育部台羅語音輸出 Demo 影片)。
四﹑低階個人電腦 (Intel Pentium-133) 即可運作。
五﹑採用開放式設計,擴充性高,並可適用多種語音字 (辭) 典。
主要功能包括:
一﹑台語及漢語語詞雙向翻譯。
二﹑台語及漢語文句雙向翻譯。
三﹑相對台語之英語/日語/漢語即時同步顯示。
四﹑相對漢語之台語/日語/英語即時同步顯示。
五﹑台語語詞及語音同步輸出 (台語有聲詞典)。
六﹑台語文句拼字檢查及語音輸出 (聲障及腦性麻痺患者代言)。
七﹑台/日/漢/英多語辭典及台語釋例即時查詢 (教育部台羅語音輸出 Demo 影片)。
八﹑文字匯入、匯出及語音存檔 (台語有聲讀本製作) 功能。
九﹑台語網頁 (教育部台羅語音輸出 Demo 影片)及外部程式 (教育部台羅語音輸出 Demo 影片)台語語音輸出。
十﹑英語/漢語字彙搜尋及索引檔製作 (教育部台羅語音輸出 Demo 影片)。
資料管理程式可說是台語語音筆記本的心臟;除了透過副程式呼叫,將控制訊息和語詞資料在框架間傳遞以外,又以索引循序法 (Indexed sequential access method) 利用關鍵值來進行多語辭典的語詞讀取、增刪、修改和回存索引等工作。為了連結資料和索引,程式使用指標 (Pointer) 和鍵值 (Key) 兩個向量來決定鍵值和位址。索引檔貯存指示資料錄位址的指標、資料錄總數、被消除資料數及後進先出的推疊指標。搜尋方式則採用減半搜尋 (Binary searching) 演算法。
範例語音輸出請按
譯自 Stopping by Woods on a Snowy Evening (by Robert Frost)
台文框和漢文框則是簡單的文書處理器。這兩個物件可進行文字輸入與輸出, 提供使用者揮灑的空間。系統對台文框文句提供拼字檢查功能及連寫、分寫容錯設計,適合初學者練習拼音。台文框同步顯示框經由文字感知器 (Text sensor) 可測知滑鼠所在位置的台語詞而將相對台羅Unicode字型、漢語、日語和英語作同步顯示。文字感知器也可藉著滑鼠按鍵動作將語詞轉化為語音輸出。
台/日/漢/英多語辭典可以預藏十萬個台語詞,相對漢語、日語及英語,分頁存放。滑鼠在台文框點按左鍵,或在漢文框指定 (反白) 某個語詞時,辭典即顯示滑鼠所在位置的台語詞。使用者也可以操作控制按鈕捲動翻頁,或指定某頁進行瀏覽。
這種功能導向設計其實是框架理論的應用和人類控制系統的模擬。這裡提到的框架,並非 Visual BASIC 的 Frame 控制項,而是一個觀念。框架理論的基本概念是將物件分割成幾個具有相關特性的小單位,每個小單位又可視需要分割成更小單位,形成一種階層樹狀結構 (Hierarchical tree) 。這種組織技巧可將複雜問題簡化,適合表達物理結構、抽象觀念、處理程序或描繪事件。具有階層關係的框架,可以傳承上階框架的內部參數,無階層關係的框架,則利用映射 (Mapping) 技巧,例如呼叫函數或程序,建立橫向關係。Visual BASIC 的表單 (Form) 就是具有框架結構的物件。在程式設計的過程中,應用框架映射技巧,把凌亂的程式碼組織起來,分別置於適當的模組,對於程式維護和執行速度的提昇,常有立竿見影的效果。
程式架構如下 (括弧內為相關功能或有階層關係之功能) :
1. 線上操作說明: 顯示操作說明
2. 檔案開啟及儲存: 分別處理台文、漢文及語音檔之開啟及存檔作業 (9,11,14,16)
3. 音色選取器: 選取男聲、女聲或童聲作語音輸出 (17,18)
4. 語音播放器: 自語音資料庫截取語音資料並進行播放 (13,15,16,17)
5. 台語翻譯器: 將漢語文句斷詞、搜尋、比對後譯成台語 (19,16)
6. 語詞同步顯示開關: 打開或關閉同步顯示語詞功能 (13,16)
7. 音效開關: 將語音輸出功能打開或關閉 (4)
8. 漢語翻譯器: 將台語文句剖析、搜尋、比對後譯成漢語 (15,16)
9. 台文文書處理器: 台文文書處理 (8,12,13,15,16,17)
10. 語詞同步顯示器: 經由文字感知器將滑鼠所在位置台語詞的相對漢語、英語和日語作同步顯示 (13,16)
11. 漢文文書處理器: 漢文文書處理 (5,12,16,19)
12. 多語辭典語料庫: 貯存台語、日語、漢語、英語語料及索引 (4,5,8,13,14,16)
13. 文字感知器: 偵測及辨識滑鼠所在位置的文字內函 (10,16)
14. 錄音器: 將指定之台語語詞同步錄音存檔 (2,16)
15. 文句剖析器: 將台語文句分解成單語,經過篩檢後存入字串陣列 (4,9,17)
16. 資料管理器: 執行語詞資料庫之管理作業 (4,5,8,9,10,11,12,13,14,17,18,19,20)
17. 語音合成器: 自語音資料庫截取所需相關語詞之語音資料再合成為語音檔 (4,9,15,16,18)
18. 二進位資料處理器: 製作語音資料庫 (16)
19. 漢語質詞庫: 貯存漢語斷詞用的質詞 (5,11,16)
20. 辭典轉換器: 將文字檔格式之辭典轉換成多語辭典資料庫 (16)
21. 外部應用程式語音輸出介面: 網頁及外部應用程式台語語音輸出 (4)
22. 聲調群剖析器: 推論引擎,知識庫,變調規則庫(語詞變調調處理器) (12,16,17,19)
23. 索引編輯器: 辨識及搜尋使用者輸入之語詞並建立台/漢/英相關語詞索引 (12,16)
24. 拼字檢查器: 將羅馬字語詞與詞典比對,並將錯誤或詞典未收錄語詞以不同顏色顯示 (12,16,19)
25. 同步語音產生器: 將輸入之漢字台語或羅馬字語詞轉換為同步語音輸出 (4,6,13,16,17,20)
26. 字元編碼轉換器: ASCII 與 UTF8 字元編碼互轉 (2,21)
語音檔的處理
自然語音輸出是主要功能之一。理論上,每個語詞至少必須對應一個語音檔,只是在 Windows 環境裡單一目錄內的檔案若超過 2000 個,搜尋速度明顯降低。數萬個基本語詞如果不以 Binary database方式建立語音資料庫,勢必無法滿足使用者對瞬間回應 (Immediately response) 的要求。由於語詞語音長短不一,同一語詞又需對應變調、不同音色等多項語音資料,必須設計三維的動態資料結構來貯存語音合成器所需的語料,並就單一語詞提供隨機存取機制。當使用者按下滑鼠,經由文字感知器,系統才可針對指定語詞做語音輸出。
語音錄製
台語可說是音樂的語言 (A language of music)。第三聲 (陰去) -第七聲 (陽去) -第一聲 (陰平) 正好是五聲音階的 Do-Me-So。所以「白鷺鷥」、「安童哥買菜」等唸謠讀起來就像唱歌一般。這種聲調語言 (Tone language) ,每一音節的音高 (Pitch) 、音量 (Volume) 、長短 (Length) 和強度 (Strength) 都對語意有決定性的影響。人工合成的語音,很難掌控台語的八聲音調特性,因此本系統採用自然語音輸出方式。然而傳統的線性錄音,必須經過移訊 (DC offset) 、雜音去除 (Noise reduction) 、順音 (Normalization) 、切割 (Trim) 等手續,才能完成一個語詞語音,是既單調、耗時又容易出差錯的作業。設計系統專屬數位錄音器勢在必行。一來可做非線性錄音,隨時將新增語詞錄製存檔,繁複的音效處理工作改由電腦代勞,甚至連存檔檔名也由文字感知器傳遞,減少鍵盤輸入造成的錯誤。原先估計完成 13200 個語音檔約需200個工時,以數位錄音器錄製只需120個工時,效率提高不少。
台漢互譯功能設計
自然語言翻譯對人類的智能是一大挑戰。不同語系間語言互譯,極為困難。嚴格說來「台漢互譯」仍在實驗階段,目前只做語詞轉換。由於台語和漢語間有高度的語法共通性,使得兩種語言經過語詞轉換後的可讀性相對提高。即令如此,台語和漢語語詞間仍有大約20%的差異 (註2)。漢台翻譯的難題之一是中文斷詞 (Word segmentation) 。拉丁語系字彙間以空格分開,不會有斷詞的困擾,中文若不經斷詞,無法進行翻譯。斷詞的關鍵技巧在於找出用來斷句的基本語詞,例如「的」「們」等出現頻率較高,語意清楚,特別是沒有上下詞連結的「質詞」 (Prime word) 。
進行翻譯時先將質詞依序讀入字串陣列,再以「比對」和「取代」方式把對應之台語語詞植入中文文句,並將中文切割成數個片斷,斷詞和語詞互換同步完成。切割後的片斷漢語如無法再行切割時,便可存入質詞庫當作質詞。這種遞迴機制 (Recursive mechanic) 可以提高斷詞效率,但是影響斷詞正確率的因素卻是質詞的優先排序 (Priority) 。質詞如何排序,在實務上頗為困難。統計常用語料的詞頻,可作為循序建立的基礎,但是兩者間並非唯一相關。
漢文本是一字一義,後來逐漸演化成一字多義。近代口語文中複字詞使用率大增,文句中某個漢字到底是單語詞還是與前後字結合成多字詞,常會造成困擾。如果斷錯文句便會弄錯語意。除了字義清楚的單字詞以外,質詞應以二字詞或三字詞為主。原則上中文質詞常以字數多寡排序,不過仍須考慮其他相關因素,否則極有可能出現類似 {台灣大學/生活/在/快樂/的/環境/裡} 的情況。
台語拼音化以後,當然不需斷詞。漢語裡的同音異義字只取一個最常用的單音詞,其餘則以複字詞代替。例如「爭」改為「爭執」,「征」改為「征討」,如此台/漢/英多語辭典中同音異義字 (詞) 的機率就降低了。換句話說,拉丁化的台語文是以「語詞」做基本單位,這種做法乃是源自於台語特有「整体語詞」的語法觀念,與北京話、客語、廣東話等羅列漢字的語法大不相同。至於質詞庫,因為用來處理中文斷詞,必需將同音異義字或詞全部納入。
台語的變調 (Tone sandhi )與聲調群 (Tone group)
構成台語的音樂性因素,除了豐富的八聲音調以外還有一個特殊的「變調」現象,規則如下:
第一聲轉第七聲,第七聲轉第三聲,第三聲轉第二聲,第二聲轉第一聲,第五聲轉第七聲以及第四聲和第八聲互轉 (註3)。通常語詞尾字保持正音,而前字必需變調。文句內的讀音也適用這個原則。「變調」意味著說話者尚未講完,從語言學的觀點看來,這種現象正是「整体語詞」概念的延伸,同時也有語意蘊函的作用。然而台語的變調現象不僅讓語音分析變得複雜,語音輸出的難度也相對提高。特別是文句裡語詞變調的情況頗多,和辭典中複字詞的變調常有差異,同一語詞,必須分別錄音,才能改善語音的輸出品質。
變調並非台語所特有,其他語言如梵語、中文或多或少都有變調的情況。然而台語變調的獨特性在於變調和本調所形成的聲調群。聲調群只有最後一個音節讀本調。換句話說,每個台語語詞都有兩種調性。複音節語詞和聲調群的前音節或中間的音節讀變調,最後音節則讀本調。因此我們可以歸納出「若且唯若語詞的集合裡最後一個語詞讀本調時,此一語詞的集合即為聲調群。」(if and only if a lexical tone was given in the end of a set of words, then the set of words was a tone group.)
台語的變調,雖然複雜卻有規則可循。更重要的是台語聲調和語意、句法結構密切相關。例如 "麻仔大 e5 燒餅 (有大麻粒的燒餅) " 和 "麻仔大 e5 燒餅 (像麻粒一般大的燒餅) " 就用聲調區別語義。而 "這間有栽花" 和 "這間有栽花 e5 厝是 guan2-tau (這間有種花的房子是我家) " 則是用上下文語意來決定前面數量詞 "這間" 的調性。
除此之外,台語語句也應用插入語詞或聲調群來修飾語氣或變更語義。例如 [A-bi2] [beh khi3 Tai5-pak.] 是由兩個聲調群組成的句子。經由插入不同調性語詞或聲調群,創造出獨特的聲調群衍生結構。
1. 插入變調語詞 siunn7: [A-bi2] [siunn7 beh khi3 Tai5-pak.] 聲調群數目不變。
2. 插入本調語詞 pai3-it: [A-bi2] [pai3-it] [beh khi3 Tai5-pak.] 聲調群數目增加為三個。
3. 插入聲調群 tse7 gu5-tshia: [A-bi2] [beh tse7 gu5-tshia] [khi3 Tai5-pak.] 聲調群數目增加為三個。
不論插入的單元是變調語詞、本調語詞或聲調群,語句的最終形式一定是以聲調群 (Tone group) 的結構呈現。
依照台語聲調群的定義及其衍生架構可以發現,台語的生成系統 (Production system) 十分明確,因而這個既科學又合邏輯的語言,可以不需經由文字系統相傳數千年之久。聲調群必是台語語言習得 (Taiwanese language acquisition) 的重要因子之一。在台語語音筆記本開發過程中,我們發現台語的變調在語詞層次不僅規則簡單,而且具有普遍性。在語句層次也能用規則處理變調程序,明確定義聲調群。聲調群不僅是組成台語語句的基本語法單元 (Syntax unit)和韻律分界 (prosodic boundary),同時也是獨特的語義單位 (Unique semantic unit) 。從現代中文 (Modern Mandarin)裡卻找不到這些現象。台語很可能是極少數以句內語詞變調方式建立聲調群結構的自然語言。
語言知識的轉換與聲調群剖析器
一般而言,語音引擎及語音合成器的設計比較偏重程式技巧。聲調群剖析器則仰賴語言知識的轉換,也就是人工智能的展現方法。語言學家Elisabeth Selkirk 認為韻律結構(prosodic structure)被用來做為語音和語法的媒介。這種現象在台語尤其明顯。台灣人的小孩在學習母語的過程中,經由變調所形成的聲調群來習得語法結構方面的知識,並且在腦海裡逐步建立一個高效率的語詞變調處理機制。因此在過去的十多年裡,我們一直試圖建立一個符號系統做為將語言專業知識 (Language expertise) 和經驗( heuristic knowledge) 轉換為知識庫的重要工具。同時應用知識表徵方法 (Knowledge representation method) 來建構人工的聲調群剖析器,也就是台語聲調調型的自動標記程式。
符號系統的設計概念,是在早期制定或修改變調規則的過程中所衍生的創意。原則上符號系統必須能夠讓語言學家方便且有效地進行語詞標記,所以必須精確定義每一組符號,並建立準則(criteria)和標記程序。然而在建構聲調群剖析器的過程中往往必須經由不斷地測試->修正->回饋->測試(Testing->modify->feedback->testing)循環,才能提高語詞變調正確率。因此,在修正階段會新增標記符號(token)或修改標記符號的定義來配合現有的規則,也可能新增或修改規則來配合標記符號。
目前我們所建立的符號系統是以預設聲調標記(default tone mark)、預設詞類(default POS mark)和模式(mode mark)三種標記組成。知識庫內的每個語詞或詞組都賦予一組包含這三種語詞標記屬性(attribute)的符號。處理台語變調時,藉著這組符號並協同以規則為基礎的變調處理器 (Rule based sandhi processor),便能將句內語詞賦予正確的調值。即使像下述例句的 ti7 和 be2,系統也能 針對相同語音,不同語義的語詞或多詞類(multiple-POS) 語詞推論出正確的詞類,予以定調。
Ti7 (筷子,名詞,讀本調) khng3 ti7 (在,介系詞,讀變調) uann2-na5-a2 lai7.
Tsit-tsiah be2 (馬,名詞,讀本調) be2 (買,動詞,讀變調) beh kah goo7-ban7.
這種應用語言學理論建構台語聲調群剖析器的方法,在實務上是以知識工程技術來模擬語言習得的實驗環境。不僅驗證人工智慧發展工具可以協助我們了解語言習得的過程,也顯示人類的語言不但是溝通的工具,也是一種思考模式。語言學和人工智能的研究必有相輔相成的密切關係。台語聲調群剖析器包含知識庫及搜尋引擎以動態連結函式庫(DLL; Dynamic-link library)的形式製作可在Windows XP/Win7 作業系統操作的ZIP檔案,可提供學術研究者評估測試使用。 台語聲調群剖析器檔案下載
外部程式語音輸出介面
近幾年來,網頁已經成為普遍而重要的大眾傳播媒體。如何讓使用者經由 Internet 傳授及學習台語時可以同步聽到正確的台語語音輸出,是程式設計的重要構想。為了讓漢文、漢羅、全羅等台語文都可在網頁或其他應用程式做語詞文句的語音輸出,我們設計一個外部應用程式介面,加上語音輸出和聲控開關。台語教材若以網頁格式或一般文字模式編輯,使用者便可經由網路或其他應用程式學習台語。此一功能設計,不需下載任何語音檔,也擴充了軟体的應用領域。
程式測試
規劃程式架構時,難免有思慮不周之處。部分功能在主體完成後添加,往往「牽一髮動全身」,除錯工作總是隨時進行。主程式經過編譯後檔案約600K Bytes,語音檔卻將近600 M Bytes。幸好資料檔可以存放光碟備用,不至佔用大量硬碟空間。製作龐大的資料檔案,確實需要不少人力。大部分資料來源格式必須進行轉換才能讓主程式使用,因此少不了要寫一些工具程式。現成的應用軟體如 WordPad、UltraEdit (文書編輯)、PaintShop Pro (繪圖)、Microangelo (Icon 繪製)、GoldWave、CoolEdit (音效處理)等,對程式開發和資料的建立,都提供不少助益。開發和測試平台用 Pentium-133 PC 和 Windows 作業系統,因此即使是入門機種,程式也可以得到滿意的執行效率。算一算,第一階段開發時程將近六個月,終於告一段落 (註6)。
系統建置所需核心技術
本系統建基於歷年來研發的軟体和相關技術 (見已發表論文),包含1998年以前在 DOS 作業系統開發的程式碼也能順利移植到 Windows。只要是ASCII編碼的語言,基本上都能經由「Vikon Multilingual Text to Speech System Compiler」建構語音輸出和對譯系統,差別只在特定詞庫和媒介語言(Medium language 註7) 的語意網路及框架必須相互對映。應用的核心技術有:
1. 自然語言處理與機器翻譯 (1984-1986)
意義表徵、概念解析、媒語檢索、二元決策樹應用
2. 三維動態資料庫 (1984-1988)
文書及資料處理、三維動態資料結構設計、資料索引及搜尋演算法、資料庫實作
3. 專家系統及規則推論 (1987-1991)
知識表徵技術、規則與邏輯推論引擎設計、多媒體整合、知識庫及專家系統實作
4. 語意網路與框架結構設計 (1987-
語意分析、常識推論、知識表徵、框架結構設計、物件導向與功能驅動設計實作
5. 使用者圖形介面 (1992-1993)
滑鼠驅動及座標偵測、圖形解碼及顯示、音效播放、外部程式介面設計實作
6. 語音、影像處理及多媒體編輯管理 (1992-1998)
音效、影像處理與合成、英漢字形映射、動畫設計、影像擷取、圖形辨識、多媒體編輯與教學系統實作
7. 語音引擎及語音合成器設計(1998-2001)
巨量語料處理、語料尋取、音節切割與合成、剖析器設計、辭彙檢索、拼字撿查、字元偵測、台語及中文語音輸出系統實作
8. 詞庫建構 (1998-
多語辭典及語料庫設計、語料蒐集與轉換、語言知識及專家經驗解析與整合、搜尋演算法及構詞分寫、連寫容錯設計
9. 語音輸出編譯器 (2001-2005)
語音輸出系統功能測試與整合、語料萃取、外部應用程式語音輸出介面設計、字元碼轉換、語音輸出編譯器實作
10. 語音模型訓練及辨識 (2005-
隱藏馬克夫模型之應用與改良、音高偵測、聲調比對、音節辨識、台語語音辨識系統實作
11. 自動回饋與學習 (2006-
訊息回饋、語言知識與邏輯判斷整合應用
12. 語言模型及認知模擬 (2008-
半自動機器學習實驗、語言模型實作
為了避免佔用太多硬碟空間,程式執行時必須從光碟讀取語音資料。硬碟有足夠空間時,將光碟 (或下載檔案) Mlttsb 目錄內的檔案複製到工作目錄 (c:\Program Files\mlttsb) 內,可加快語音讀取速度。
用滑鼠在台語詞上點按左鍵,即可聽到該字詞的語音 (此功能可 On/Off) 並顯示字詞在辭典內的位置 (註5),使用者可在辭典內上下翻頁搜尋。句子或文章輸入後,語音合成器會將反白部分連續讀出 (此功能可 On/Off) ,翻譯器則將反白部分漢譯。無法漢譯的語詞或外來語則保留原文成為漢羅文体。
輸入好的臺語、漢譯和語音都可分別存檔備用。已存檔的台文可再打開繼續編輯或修改。其他文書處理器如 Word、WordPad 內的文字也能在反白複製後用 Ctrl-v 貼到台文框。台文框數字調符之文句內容也可反白後按 Ctrl-c 複製貼到其他文書處理器。Ctrl-x (剪下)、Ctrl-z (復原)、Ctrl-a (全選) 都可協助使用者進行文書處理工作。上述功能亦可按滑鼠右鍵列出選單,CopyAsUnicode (教育部台羅語音輸出 Demo 影片) 並能將反白的ASCII台文即時轉換為台語 Unicode 格式貼到 Notepad、Word 等可以處理 Unicode 的外部程式。SpellCheck 可做拼字檢查。詞典已有收錄的語詞以黑色字體顯示,詞典尚未收錄但可合成的語詞以藍色字體顯示,無法合成或與構詞法不合的語詞則以紅色字體顯示。
 外部應用程式語音輸出介面及台語文格式轉換
以滑鼠左鍵點按此圖,可開啟外部程式語音輸出介面
外部應用程式語音輸出介面及台語文格式轉換
以滑鼠左鍵點按此圖,可開啟外部程式語音輸出介面  。用滑鼠將網頁或文件內容反白後,
點按語音合成器
。用滑鼠將網頁或文件內容反白後,
點按語音合成器  ,可以聆聽 以 Unicode (調符) 或 ASCII (數字) 編碼的漢文、漢羅、全羅等台語
文句語音輸出並將外部程式的台語文轉為ASCII數字格式,匯入台文框 (教育部台羅語音輸出 Demo 影片)。
若只做台語文格式轉換,則以滑鼠右鍵點按 再用左鍵點按
,可以聆聽 以 Unicode (調符) 或 ASCII (數字) 編碼的漢文、漢羅、全羅等台語
文句語音輸出並將外部程式的台語文轉為ASCII數字格式,匯入台文框 (教育部台羅語音輸出 Demo 影片)。
若只做台語文格式轉換,則以滑鼠右鍵點按 再用左鍵點按  ,
在台文框按右鍵再選「貼上」可將外部程式的 ASCII 台語文匯入台文框。
,
在台文框按右鍵再選「貼上」可將外部程式的 ASCII 台語文匯入台文框。
 字彙搜尋
點按此圖可以進行以英文或漢文來搜尋台語字彙並製作索引檔 EINDEX.TXT 及
CINDEX.TXT。搜尋後找到的台語語詞,反白後也能做語音輸出。
字彙搜尋
點按此圖可以進行以英文或漢文來搜尋台語字彙並製作索引檔 EINDEX.TXT 及
CINDEX.TXT。搜尋後找到的台語語詞,反白後也能做語音輸出。
 操作說明
顯示圖形操作介面及說明。
操作說明
顯示圖形操作介面及說明。
 開啟檔案 (台文)
先用滑鼠點選台文框 (開啟台文檔) 或漢文框 (開啟漢文檔),再點按此圖可以打開已經建好的台文
或漢文檔案。
開啟檔案 (台文)
先用滑鼠點選台文框 (開啟台文檔) 或漢文框 (開啟漢文檔),再點按此圖可以打開已經建好的台文
或漢文檔案。
 另存新檔 (台文)
要建立新的台文檔案可直接在台文框輸入文句。不論是新建檔案或
修改舊檔都可點按此圖,將台文框內容以ASCII文字檔格式及 Unicode 調符檔儲存。
另存新檔 (台文)
要建立新的台文檔案可直接在台文框輸入文句。不論是新建檔案或
修改舊檔都可點按此圖,將台文框內容以ASCII文字檔格式及 Unicode 調符檔儲存。
 存語音檔 (有聲讀本製作)
將目前正在朗讀的台文語音以 wave 檔格式儲存。此功能可直接製作台語有聲讀本,不需外掛錄音程式。
存語音檔 (有聲讀本製作)
將目前正在朗讀的台文語音以 wave 檔格式儲存。此功能可直接製作台語有聲讀本,不需外掛錄音程式。
 存漢文檔
將漢文框內容以文字檔格式儲存。
存漢文檔
將漢文框內容以文字檔格式儲存。
 變換聲音
選擇以男聲、女聲或童聲播出 (本版以男聲播出)。
變換聲音
選擇以男聲、女聲或童聲播出 (本版以男聲播出)。
語音合成及輸出
語音合成器會將台文框指定 (反白) 的語詞或文句逐字讀出。按右鍵可選擇讀速。
 漢文台譯
翻譯器會將漢文框中指定 (反白) 的語詞或文句內容斷詞後譯成台文。
無法台譯的語詞或外語則保留原文成為漢羅文体。篇幅較長的文章請
分段翻譯。
漢文台譯
翻譯器會將漢文框中指定 (反白) 的語詞或文句內容斷詞後譯成台文。
無法台譯的語詞或外語則保留原文成為漢羅文体。篇幅較長的文章請
分段翻譯。
 同步顯示及「隨打隨聽」開關 (on/off)
點按此圖可以打開或關閉同步顯示語詞功能。
打開同步顯示:
當滑鼠在台文框內移動時會將滑鼠所在位置台語詞的相對漢語、英語
和日語作同步顯示。
關閉同步顯示:
尚未熟習台語的使用者在寫作台文時,往往無法拚出正確的語詞,
這時要將同步顯示開關關閉,然後把滑鼠移到漢文框內,輸入漢字時
便可同步聽到台語語音。將漢語詞反白後也可顯示相對的台文語詞並
聽到台語語音。同樣的,在台文框輸入台語語詞後按空白鍵或 Enter
鍵也能立即聽到台語語音以判定輸入語詞是否正確。
同步顯示及「隨打隨聽」開關 (on/off)
點按此圖可以打開或關閉同步顯示語詞功能。
打開同步顯示:
當滑鼠在台文框內移動時會將滑鼠所在位置台語詞的相對漢語、英語
和日語作同步顯示。
關閉同步顯示:
尚未熟習台語的使用者在寫作台文時,往往無法拚出正確的語詞,
這時要將同步顯示開關關閉,然後把滑鼠移到漢文框內,輸入漢字時
便可同步聽到台語語音。將漢語詞反白後也可顯示相對的台文語詞並
聽到台語語音。同樣的,在台文框輸入台語語詞後按空白鍵或 Enter
鍵也能立即聽到台語語音以判定輸入語詞是否正確。
 音效開關
點按此圖可以打開或關閉語音輸出功能。
音效開關
點按此圖可以打開或關閉語音輸出功能。
 台文漢譯
翻譯器會將台文框中指定 (反白) 的語詞或文句內容譯成漢文。
無法漢譯的語詞或外來語則保留原文成為漢羅文体。篇幅較長的文章請
分段翻譯。
台文漢譯
翻譯器會將台文框中指定 (反白) 的語詞或文句內容譯成漢文。
無法漢譯的語詞或外來語則保留原文成為漢羅文体。篇幅較長的文章請
分段翻譯。
 關閉程式
結束程式,返回 Windows 作業系統。
關閉程式
結束程式,返回 Windows 作業系統。
二次戰後的長期戒嚴使得台灣人的尊嚴與母語教育幾乎喪失殆盡。曾幾何時,台語就像猶太人胸前的黃牌 (參見被遺忘的年代),成了低俗不雅的象徵。
年輕一輩的台灣人不僅不能寫,不願學,甚至也不能說出流利的母語。台語是否會在這股潛藏的危機裡逐漸消失,實在值得大家深思。語言學家王育德博士,畢生致力研究台語。他不僅揭櫫台語聲調群的研究,也是第一位將台灣話的辭典編纂出版的台灣人。日人遠山景久曾在王博士的追悼辭表示「民族的原點既非人種亦非國籍,而是語言和文字。」王育德博士的一生,正是認同台灣的最佳寫照。
台語是極為優雅的語言,也是少數目前 (2000) 能應用電腦做語音輸出的語言之一。經由本系統,不論使用羅馬字或是漢字,都可以將台語文字化和電腦化。希望有一天,台灣人都能用母語思考、寫作,敘述內心的感覺。本版收錄 60000 個台語語詞,詞庫陸續擴充中。敬請指教,並歡迎提供意見。
台語語音輸出專案製作
如果你會說台語,又想擁有自己獨特的語音輸出,我們可以協助你製作專屬於你的台語電腦語音輸出軟体。詳情請洽: poirotdavid@yahoo.com.tw 張佑竹。
軟體下載 (若無法自雲端下載,請用 e-mail 和作者連繫。)
雖然仍有改善的空間,2021年版台語語音筆記本的功能,已經達成1998年設定的目標。在程式設計過程中遇到最大的挑戰是讓人類了解語言的語法,句型和運作過程是一回事,然而教電腦學習人類語言的語法,句型和運作過程卻是另一回事。我將這個開發多年的軟體呈獻給和我一樣,想閱讀台語文章和學習台語書寫的人使用,希望對他們的學習能有所助益,也歡迎大家提供改善建議。已下載舊版安裝檔的使用者請將更新版檔案下載,解壓後將檔案複製到預設工作目錄 c:\TSN-TRO\ 或安裝時指定的台語語音筆記本工作目錄。
台語語音筆記本軟體安裝檔案下載
台語語音筆記本更新版檔案下載
2
取樣值為13819個台語常用語詞,誤差估計值2.5%。分別就
1. 與中文間音義相同可用漢字書寫之台語語詞
2. 中文無此用法,但可用漢字書寫之台語語詞
3. 僅有中文同義字之台語語詞
4. 無中文同義字之台語語詞
等四項進行分類,同音異義詞及多義詞併入與第三類互斥計算。
3
依據周辨明、王育德的研究 (參見 Chiu Bien-Ming, The phonetic structure and tone behavior in Hagu and their relation to certain questions in Chinese, T'oung Pao 28, 245-342, Leidenu, 1931. 王育德, 臺灣語の聲調, 中國語學 41, 3-11, 1955),台語第四聲與第八聲互轉,僅用於以 p、t、k結束的入聲韻。以 h 結束的入聲韻,要用第四聲轉第二聲,第八聲轉第三聲的規則,獨自變調。台語除八聲外,還有一個介於三聲和四聲間的弱音 0 (輕) 聲。
雙音節語詞為了表示本身是一個完整單位,具有重音核心。原則上重音核心位於第二音節,換句話說,重音所在的音節保有原來的聲調,而在前面的音節發生變調的現象。但是輕聲則在最後音節,而把重音核心移至前一音節,此為例外。
4
由於台語構詞法和語詞標準化尚未定案,本系統第二版媒介語言將以 h 結束的入聲韻實詞改用第四聲轉第二聲,第八聲轉第三聲的規則變調。以 h 結束的入聲韻虛詞仍沿用第四聲與第八聲互轉的方式變調。輕聲暫以第三聲標示。強辭記號則用 「`」,記號前後都標實調。
5
「彙集雅俗通十五音」 韻書內文言音印紅字,白話音及訓讀都印黑字。閩南基督教聖詩則以小圓圈符號標記文音。台語中何者為白話音,何者為訓讀,實務上頗難區別。在台語語詞尚未標準化前,語詞標調及錄音原則上以作者習用的台南腔為主,疏誤之處,將於改版時訂正。相對漢語語詞,僅供參考,待部頒語詞定案後一併修正。
6
「台語語音筆記本」和「中文漢語拼音讀寫系統」都是採用 Vikon Multilingual Text to Speech System (MLTTS) Compiler 進行編譯之語音輸出應用軟體。MLTTS 除了配備語音引擎以外,還能整合及編譯各種類型的語料和工具程式,並進行語詞檢索 (Word retrieval)、文句剖析 (Sentence parsing)、機器學習 (Machine learning) 與自動回饋 (Auto-feedback) 等功能測試。其組織架構適用於以大詞庫 (Corpus) 及語意單位 (Semantic unit) 為基礎的語料處理,也是框架理論和語意網路的延伸應用。
7
現存的文字語言或因通行已久,或因約定成俗,無法以電腦做邏輯規則處理,必須建立電腦化的人工語言做為媒介。媒介語言的符號和構詞法不受自然語言約束,語法簡單,語意明確,因此適合常規處理,也能建立與自然語言映射的機制。
8
台語語音筆記本及MLTTS 語音輸出編譯器,包含軟體規畫、程式設計、測試、除錯、技術文件編撰、語料庫、知識庫建置, 自1998年迄今,累計逾30000個開發工時。
[ 研究日誌記事摘要 |
台語聲調群剖析器 |
中文作品 |
回主畫面 |
參考資料
]
This website is sponsored
by VIKON Corp.
Copyright July 1996.
All rights reserved.
Last update : 2018-02-10
有什麼建議嗎 ? 來信請寄:
 vikontony@gmail.com
vikontony@gmail.com